本文共 3870 字,大约阅读时间需要 12 分钟。
一、问题的由来
URL就是网址只要上网就一定会用到。

一般来说URL只能使用英文字母、阿拉伯数字和某些标点符号不能使用其他文字和符号。比如世界上有英文字母的网址"http://www.abc.com"但是没有希腊字母的网址"http://www.aβγ.com"读作阿尔法-贝塔-伽玛.com。这是因为网络标准做了硬性规定
"...Only alphanumerics [0-9a-zA-Z], the special characters "$-_.+!*'()," [not including the quotes - ed], and reserved characters used for their reserved purposes may be used unencoded within a URL."
"只有字母和数字[0-9a-zA-Z]、一些特殊符号"$-_.+!*'(),"[不包括双引号]、以及某些保留字才可以不经过编码直接用于URL。"
这意味着如果URL中有汉字就必须编码后使用。但是麻烦的是RFC 1738没有规定具体的编码方法而是交给应用程序浏览器自己决定。这导致"URL编码"成为了一个混乱的领域。
下面就让我们看看"URL编码"到底有多混乱。我会依次分析四种不同的情况在每一种情况中浏览器的URL编码方法都不一样。把它们的差异解释清楚之后我再说如何用Javascript找到一个统一的编码方法。
二、情况1网址路径中包含汉字
打开IE我用的是8.0版输入网址"http://zh.wikipedia.org/wiki/春节"。注意"春节"这两个字此时是网址路径的一部分。

查看HTTP请求的头信息会发现IE实际查询的网址是"http://zh.wikipedia.org/wiki/%E6%98%A5%E8%8A%82"。也就是说IE自动将"春节"编码成了"%E6%98%A5%E8%8A%82"。
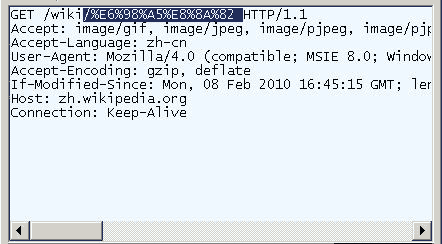
我们知道"春"和"节"的utf-8编码分别是"E6 98 A5"和"E8 8A 82"因此"%E6%98%A5%E8%8A%82"就是按照顺序在每个字节前加上%而得到的。具体的转码方法请参考我写的。
在Firefox中测试也得到了同样的结果。所以结论1就是网址路径的编码用的是utf-8编码。
三、情况2查询字符串包含汉字
在IE中输入网址"http://www.baidu.com/s?wd=春节"。注意"春节"这两个字此时属于查询字符串不属于网址路径不要与情况1混淆。

查看HTTP请求的头信息会发现IE将"春节"转化成了一个乱码。
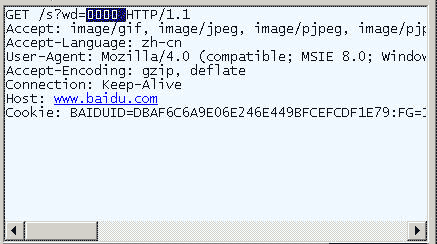
切换到十六进制方式才能清楚地看到"春节"被转成了"B4 BA BD DA"。
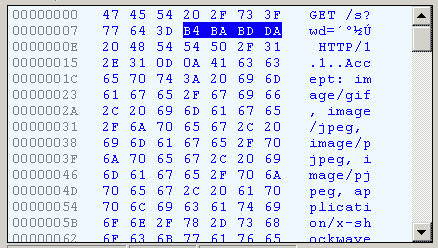
我们知道"春"和"节"的GB2312编码我的操作系统"Windows XP"中文版的默认编码分别是"B4 BA"和"BD DA"。因此IE实际上就是将查询字符串以GB2312编码的格式发送出去。
Firefox的处理方法略有不同。它发送的HTTP Head是"wd=%B4%BA%BD%DA"。也就是说同样采用GB2312编码但是在每个字节前加上了%。
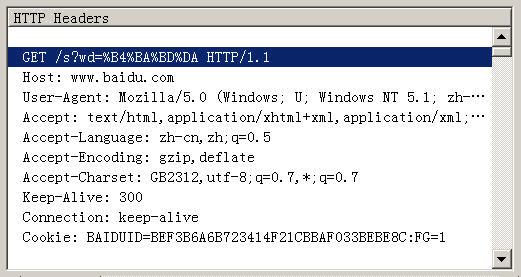
所以结论2就是查询字符串的编码用的是操作系统的默认编码。
四、情况3Get方法生成的URL包含汉字
前面说的是直接输入网址的情况但是更常见的情况是在已打开的网页上直接用Get或Post方法发出HTTP请求。
根据台湾中兴大学这时的编码方法由网页的编码决定也就是由HTML源码中字符集的设定决定。
<meta http-equiv="Content-Type" content="text/html;charset=xxxx">
如果上面这一行最后的charset是UTF-8则URL就以UTF-8编码如果是GB2312URL就以GB2312编码。
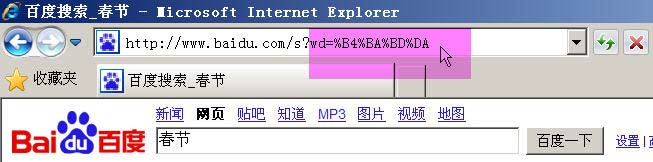
举例来说百度是GB2312编码Google是UTF-8编码。因此从它们的搜索框中搜索同一个词"春节"生成的查询字符串是不一样的。
百度生成的是%B4%BA%BD%DA这是GB2312编码。
Google生成的是%E6%98%A5%E8%8A%82这是UTF-8编码。
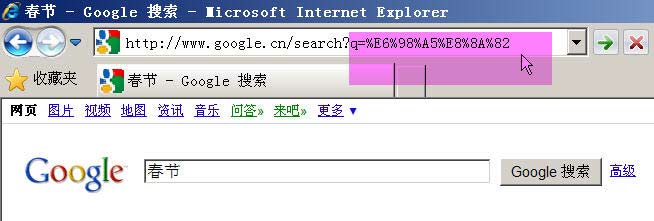
所以结论3就是GET和POST方法的编码用的是网页的编码。
五、情况4Ajax调用的URL包含汉字
前面三种情况都是由浏览器发出HTTP请求最后一种情况则是由Javascript生成HTTP请求也就是Ajax调用。还是根据吕瑞麟老师的文章在这种情况下IE和Firefox的处理方式完全不一样。
举例来说有这样两行代码
url = url + "?q=" +document.myform.elements[0].value; // 假定用户在表单中提交的值是"春节"这两个字
http_request.open('GET', url, true);
那么无论网页使用什么字符集IE传送给服务器的总是"q=%B4%BA%BD%DA"而Firefox传送给服务器的总是"q=%E6%98%A5%E8%8A%82"。也就是说在Ajax调用中IE总是采用GB2312编码操作系统的默认编码而Firefox总是采用utf-8编码。这就是我们的结论4。
六、url传参时参数值中包含=或&这种特殊字符
Ukey=value这种传参方式式中 Value中包含&或者 = 怎么办呢。
比如说“name1=value1”,其中value1的值是“va&lu=e1”字符串那么实际在传输过程中就会变成这样“name1=va&lu=e1”。我们的本意是就只有一个键值对但是服务端会解析成两个键值对这样就产生了奇异。
另外不同的操作系统、浏览器、不同的网页字符集charset会对你的传值造成影响呢。
七、Javascript函数escape()
好了到此为止四种情况都说完了。
假定前面你都看懂了那么此时你应该会感到很头痛。因为实在太混乱了。不同的操作系统、不同的浏览器、不同的网页字符集将导致完全不同的编码结果。如果程序员要把每一种结果都考虑进去是不是太恐怖了有没有办法能够保证客户端只用一种编码方法向服务器发出请求
回答是有的就是使用Javascript先对URL编码然后再向服务器提交不要给浏览器插手的机会。因为Javascript的输出总是一致的所以就保证了服务器得到的数据是格式统一的。
Javascript语言用于编码的函数一共有三个最古老的一个就是escape()。虽然这个函数现在已经不提倡使用了但是由于历史原因很多地方还在使用它所以有必要先从它讲起。
实际上escape()不能直接用于URL编码它的真正作用是返回一个字符的Unicode编码值。比如"春节"的返回结果是%u6625%u8282也就是说在Unicode字符集中"春"是第6625个十六进制字符"节"是第8282个十六进制字符。

它的具体规则是除了ASCII字母、数字、标点符号"@ * _ + - . /"以外对其他所有字符进行编码。在\u0000到\u00ff之间的符号被转成%xx的形式其余符号被转成%uxxxx的形式。对应的解码函数是unescape()。
所以"Hello World"的escape()编码就是"Hello%20World"。因为空格的Unicode值是20十六进制。

还有两个地方需要注意。
首先无论网页的原始编码是什么一旦被Javascript编码就都变为unicode字符。也就是说Javascipt函数的输入和输出默认都是Unicode字符。这一点对下面两个函数也适用。

其次escape()不对"+"编码。但是我们知道网页在提交表单的时候如果有空格则会被转化为+字符。服务器处理数据的时候会把+号处理成空格。所以使用的时候要小心。
八、Javascript函数encodeURI()
encodeURI()是Javascript中真正用来对URL编码的函数。
它着眼于对整个URL进行编码因此除了常见的符号以外对其他一些在网址中有特殊含义的符号"; / ? : @ & = + $ , #"也不进行编码。编码后它输出符号的utf-8形式并且在每个字节前加上%。
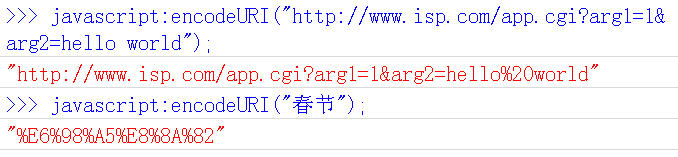
它对应的解码函数是decodeURI()。

需要注意的是它不对单引号'编码。
九、Javascript函数encodeURIComponent()
最后一个Javascript编码函数是encodeURIComponent()。与encodeURI()的区别是它用于对URL的组成部分进行个别编码而不用于对整个URL进行编码。
因此"; / ? : @ & = + $ , #"这些在encodeURI()中不被编码的符号在encodeURIComponent()中统统会被编码。至于具体的编码方法两者是一样。
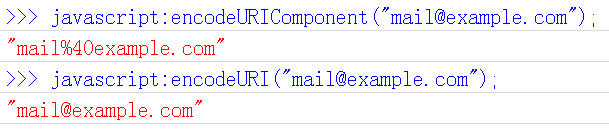
它对应的解码函数是decodeURIComponent()。
十、 最佳解决方案
对参数值用encodeURIComponent()进行编码。
例如
跳转页面链接设置为http://passport.baidu.com/?logout&aid=7&imageUrl='+encodeURIComponent("http://cang.baidu.com/bruce42)
然后在跳转后的页面获取参数的值
var imageUrl = decodeURIComponent(getQueryString('imageUrl'));
转载地址:http://cnbel.baihongyu.com/